








Knowledge Distillation in Neural Networks: Enhancing Model Efficiency
Neural networks are important devices for artificial intelligence which facilitate rapid data processing over large volumes. Increasingly complex and big models accompany an increase in the number of data Resource-constrained devices like mobiles and tablets introduce their own hurdles while attempting to implement AI. The idea of compressing deep models is gaining traction.
Understanding Knowledge Distillation: A Teacher-Student Model
A teacher would educate their students in a university or school. The student models similarly learn from the teacher model through inference based on its predictions. Then they can accomplish tasks of same quality. This process lets us compact the bigger model, thereby enabling its deployment on limited-resource gadgets.
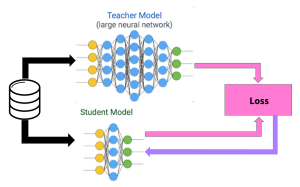
The Concept of Knowledge Transfer: Soft Targets vs. Hard Targets
Rather than using the one-hot encoding for classes, knowledge distillation utilizes the probabilities produced by the teacher model’s classes. Because they include more information per training example, soft targets promote knowledge transfer more efficiently.
Training the Teacher-Student Model
This learning session initiates through teaching the educator machine using a wide database such as MNIST. The student model trains itself using the soft targets from the teacher model and the target data it generates itself. The usage of easy goals assists in improving the student’s understanding process, allowing for comparable precision with the instructor.
Differences from the Original Paper
We modified the training process slightly for this reproduction. Rather than utilizing dropout, we merely leveraged weight decay during training By messing with how much it runs, we can boost these two types of models. However, notwithstanding those inconsistencies, the general conclusion and trend of the paper remain constant.
Effective modeling is accomplished via knowledge distillation
Our reproduction demonstrated that knowledge distillation is effective. Distilled student models showed higher performance than their counterparts. This technique was found especially useful when handling a transfer set where the learner model performed extraordinarily well, despite not coming across particular classes during training.
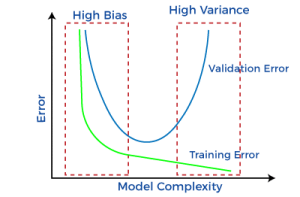
Parameter effects and student model accuracy
We found out that the temperature hyper-parameter affects knowledge transfer significantly. Units in the models must be below 100 for temperature to enhance the performance and sustain the velocity.
Bias reduces student model accuracy
Using a bias value optimization to produce a suitable result increased the possibility that transfer sets would be identified with accuracy.
Concluding Thoughts
With knowledge distillation, neural networks are optimized and enhanced. Transferring knowledge from big models to small ones lets us reach equivalent precision while decreasing complexity. Opening doors for low-resource deployments with high performance. This essay illustrates the capacity of knowledge distillation for expertise transferring from sophisticated to small neural networks.
